4.10 Parallelism via Instruction
🔑Table of Contents
- Instruction-Level Parallelism (ILP)
- Multiple Issue (다중 내보내기)
- Speculation (추정)
- Compiler/Hardware Speculation (컴파일러와 하드웨어에서 추정)
- Speculation and Exceptions (추정과 예외)
- Static Multiple Issue (정적 다중 내보내기)
- Scheduling Static Multiple Issue
- MIPS with Static Dual Issue
- MIPS with Static Dual Issue
- Hazards in the Dual-Issue MIPS
- Scheduling 예제
- Loop Unrolling
- Dynamic Multiple Issue
- Dynamic Multiple Scheduling
- Dynamically Scheduled CPU
- Register Renaming
- Speculation(추정)
- Why Do Dynamic Scheduling?
- Does Multiple Issue Work?
- Fallacies
- Pitfalls
- Concluding Remarks
📌Instruction-Level Parallelism (ILP)
명령어 수준 병렬성
- 파이프라이닝 : 여러 명령어들을 병렬적으로 수행
- 명령어 수준 병렬성을 향상하는 법
- 더 깊은 파이프라인
- 파이프라인의 단계를 세분화해 각 단계에서 더 적은 작업을 수행하도록 설계
- 한 단계의 작업량이 줄어 클록 주기 짧아짐 , 속도증가
- 단계 수는 증가해 명령어 실행 지연이 늘어남
- 다중 내보내기
- 여러 명령어를 동시에 처리할 수 있는 방식으로 파이프라인을 복제하거나 병렬로 구성
- 한 사이클 동안 여러 명령어를 동시에 실행 가능.
- CPI < 1로 감소해 IPC를 사용
- 4GHz 클록 속도를 가진 4-way Multiple Issue CPU:
- Peak IPC=4 Peak CPI = 0.25 ,BIPS=4×4GHz=16BIPS (160억 IPS)
- 더 깊은 파이프라인
📌 Multiple Issue (다중 내보내기)
- 정적 다중 내보내기
- 컴파일러가 명령어 그룹 결정
- 어떤 명령어가 어느 사이클에서 실행될지 컴파일러가 사전에 결정
- 명령어들 묶어 내보내기 슬롯에 패키징
- 내보내기 슬롯 : 한 사이클 동안 병렬로 처리할 명령어들의 그룹.
- 컴파일러가 데이터 해자드, 제어 해자드를 분석해 회피시켜줌
- 컴파일러가 명령어 그룹 결정
- 동적 다중 내보내기
- CPU가 명령어 스트림을 분석하고, 각 사이클에 동시에 실행 가능한 명령어를 선택해 실행
- 실행순서 조정 가능해 비순차 실행 가능
- 컴파일러가 보조해줌 (명령어 순서 재배열해 병렬 시행 도움)
- CPU는 고급기술을 사용해 해자드 해결
- CPU가 명령어 스트림을 분석하고, 각 사이클에 동시에 실행 가능한 명령어를 선택해 실행
📌 Speculation (추정)
- 어떤 명령어의 결과나 실행 흐름을 미리 추정하는것
- 예상되는 결과로 작업을 미리 실행
- 검증
- 맞았다면 작업을 진행
- 틀리면 작업 roll-back(취소)후 올바른 작업 수행
- 정적, 동적 다중 내보내기에서 모두 사용
- 예 :
- 브랜치 예측해서 틀리면 roll back
- lw에서 특정 메모리 주소에서 값을 읽는 상황
- 미리 읽어둔 데이터(캐시)를 사용해 처리
- 해당 주소값 변했음 roll back
📌 Compiler/Hardware Speculation (컴파일러와 하드웨어에서 추정)
- 컴파일러는 명령어 순서를 재배열 할 수 있음
- 예상 실패시 복구명령어를 추가
- 하드웨어는 실행할 명령어 미리 검사해 병렬로 수행 가능한 작업을 활용
- 명령어 수행후 버퍼에 저장
- 추측이 맞으면 결과사용, 아니면 버퍼를 flush
📌 Speculation and Exceptions (추정과 예외)
- 추정 중 명령어를 미리 실행하다가 예외가 발생한다면
- 명령어 실행이 완료되었을 수도, 진행 중일 수도, flush될 수도 있음
- null pointer체크 전에 수행된 load명령어가 잘못된 메모리 주소에 접근해 예외 발생
- 정적추정
- 컴파일러가 관리
- ISA의 도움을 받아 예외를 지연시킬 수 있음
- 동적 추정
- 하드웨어가 런타임에서 예외를 관리
- 예외를 즉시처리하지 않고 버퍼에 저장해 나중에 처리한다
📌 Static Multiple Issue (정적 다중 내보내기)
- 컴파일러가 명령어들을 내보내기 슬롯으로 그룹화
- 컴파일러가 명령어를 분석해 필요로하는 파이프라인 자원에 의해 결정됨
- 한 사이클에 동시 실행, 파이프라인의 서로 다른 단계에서 처리됨
- VLIM
- 내보내기 packet을 하나의 아주 긴 명령어 처럼 간주
- 여러개의 동시 작업들로 지정
📌 Scheduling Static Multiple Issue
- 컴파일러는 반드시 모든/몇몇 hazard를 제거해야 한다.
- instruction들의 순서를 재배치하고, issue packet들로 묶는다.
- 한 packet은 의존성(dependency)이 없도록 묶여진 것들이다(그러니 동시에 실행 가능).
- 다른 packet들 사이에는 좀 의존성이 있을 수도 있다.
- ISA에 따라 다르다
- 만약 필요하다면, NOP(stall, bubble)을 삽입한다.
📌 MIPS with Static Dual Issue
2개씩 동시실행
- 2-issue packets
- 1 ALU/branch instruction
- 1 load/store instruction
- 64-bit 정렬(aligned)
- 32-bit*2 = 64-bit
- ALU/branch, 그 후 load/store
| 주소 | instruction type | pipeline stages | ||||||
| n | ALU/branch | IF | ID | EX | MEM | WB | ||
| n+4 | load/store | IF | ID | EX | MEM | WB | ||
| n+8 | ALU/branch | IF | ID | EX | MEM | WB | ||
| n+12 | load/store | IF | ID | EX | MEM | WB | ||
| n+16 | ALU/branch | IF | ID | EX | MEM | WB | ||
| n+20 | load/store | IF | ID | EX | MEM | WB | ||
ㆍ8*4=32. 32-bit씩 2개가 동시에. 주소의 앞뒤 정렬순서는 ALU/branch 이후 load/store.
ㆍ사용되지 않는 instruction은 nop으로 충진(packet으로 잘 나눠도 bubble이 발생할 수는 있으니).
📌 MIPS with Static Dual Issue
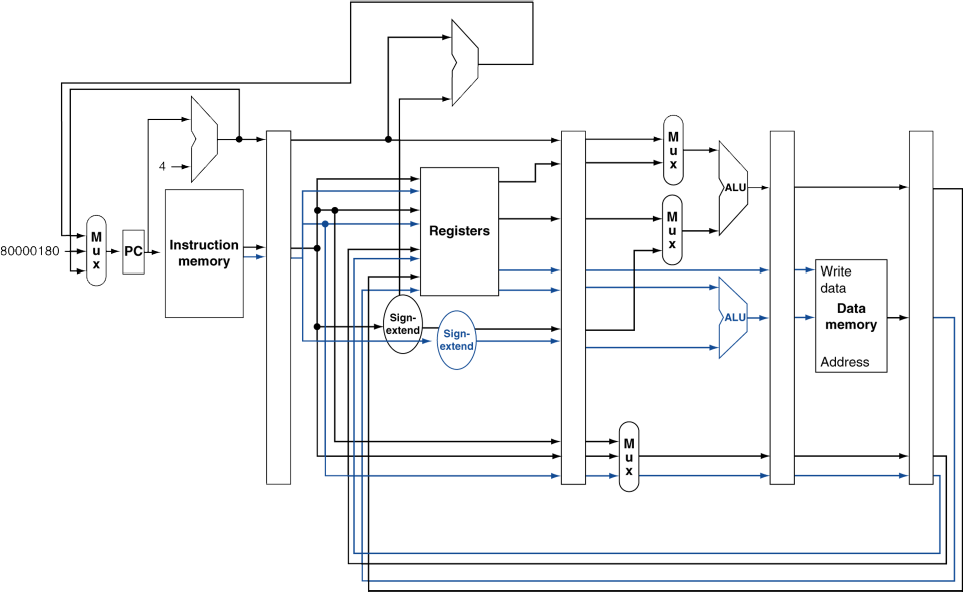
- ALU/branch는 기존 장치를 이용한다고 하면,
- load/store를 위한 장치와 datapath 등이 추가되었다.
- (여기서는 branch를 ID stage로 당긴 모델이 아닌, 예전 모델 기준인듯.)
- 레지스터는 함께 사용. 새로운 경로가 복제되듯이 추가됨.
- 그리고, ALU/branch는 메모리에서 가져오거나 쓰지 않으므로, 바로 통과하여 레지스터로 WB 하는 경로로 수정되어 있음.
📌 Hazards in the Dual-Issue MIPS
- 병렬적으로 많은 명령어를 동시에 실행하는(execute) 형태.
- EX data hazard
- single-issue에서도 stall을 피하기 위해 forwarding 기법을 사용했었음.
- 이제는 같은 packet에서 ALU 결과값을 load/store에 이용하지는 않을 것임.
- add $t0, $s0, $s1
- load $s2, 0($t0)
- 종속성이 있으므로, 다른 packet으로 나누었을 것임(같은 타이밍은 아예 불가능).
- 다른 타이밍(다른 packet)에도 여전히 stall은 발생.
- (single-cycle도 한 단계 늦은 타이밍에도 stall이 발생해서 forwarding했음.)
- load-use data hazard
- 여전히 1-cycle의 지연(latency)을 필요로하지만, 이번에는 2 instruction들이 동시진행된다는 점.
- 더욱 적극적인 scheduling이 필요해진다.
📌 Scheduling 예제
*dual-issue MIPS를 위한 Scheduling
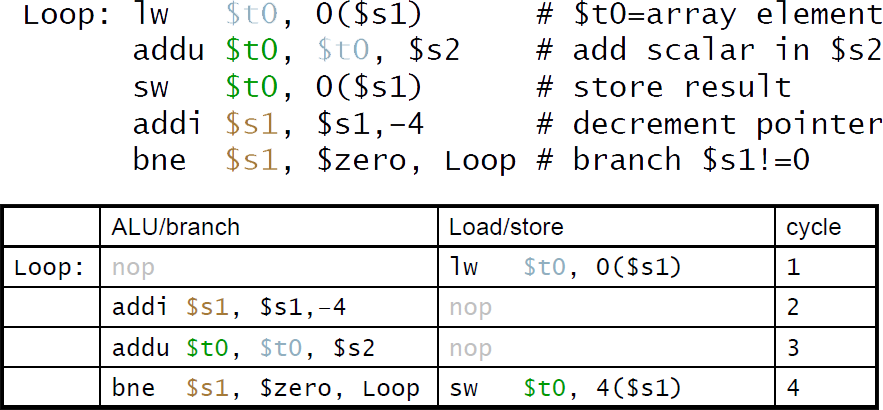
ㆍIPC = 5/4 = 1.25 (c.f., peak IPC = 2)
명령어 개수 / 사이클 개수
📌 Loop Unrolling
반복문을 풀어헤치기
- loop body를 복제하여 더 병렬적인 형태로 풀어버리는 것.
- loop-control overhead를 줄여준다.(한 번에 여러번의 내용을 실행해서, branch가 줄어듦)
- 복제(loop 내용)마다 다른 레지스터를 사용하도록 한다.
- 레지스터 재명명이라고 함
- loop에서 유발되는 "반의존성(anti-dependency)"를 방지
- 같은 레지스터를 load한 후 다시 store할 때. aka. "name dependence". 레지스터 이름을 재사용. (이름 의존성)
- 위의 동일한 예제(Loop)를 풀어헤친것
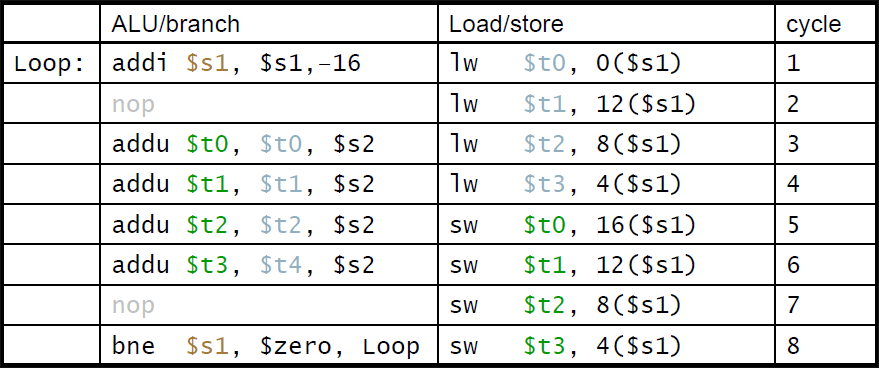
*IPC = 14/8 = 1.75
ㆍ기존의 1.25보다 상승하여 더 2(peak IPC)에 근접해짐.
ㆍ하지만 code 길이(instruction memory size)와 레지스터의 비용은 증가함.
📌 Dynamic Multiple Issue
- 수퍼스칼라 processors (내보낼 명령어수)
- CPU가 각각의 cycle에 어떤 instruction이 issue될지 결정하는 것.
- runtime에 동적으로(컴파일러가 아닌 CPU가 하니 runtime).
- CPU가 향후 instruction들을 미리 내다보고, 시험해본 후, 순서를 정하여 실제로 실행.
- structure hazards, data hazards를 방지해줌.
- 컴파일러의 scheduling의 필요성을 줄임(필요에 따라 보조적으로 할 수는 있음).
- 그러나 여전히 도움이 될 수는 있음(필요에 따라 보조적으로 할 수는 있음).
- 전체적으로 code의 제어권은 CPU가 가짐. (의도한 목적을 유지하도록 명령어 실행)
📌 Dynamic Multiple Scheduling
- CPU가 stall을 방지하기 위해 instruction들을 순서에 상관없이 비순차 실행하도록 허용하는 것.
- 하지만 레지스터에 결과를 반영(commit)하는 것은 순서대로 해야한다.
*예시
lw $t0, 20($s2)
addu $t1, $t0, $t2
sub $s4, $s4, $t3
slti $t5, $s4, 20
ㆍaddu가 lw 때문에 기다리는 동안 sub을 시작할 수 있게 해줌.(비순차)
📌 Dynamically Scheduled CPU

(데이터 종속적이지 않아서 순서 상관없이 실행될 수 있는 애들을 말하는 것 같음.
어차피 CPU가 issue 순서는 미리 시험해본 후 한거니까.. hazard 방지해서)
✨✨✨✨
📌 Register Renaming (레지스터 재명명)
superscalar processors의 중요한 특징 중 하나
- 어떤 instruction이 어떤 레지스터를 사용하는 경우, 원래는 해당 레지스터를 사용해야 하고, 그걸 위해 기다리거나 했지만, 다른 레지스터를 이용가능하도록 하여 그 레지스터를 사용.
- instruction의(code의) 표기된 레지스터와, 실제 수행의 레지스터가 다를 수 있다는 것.
- reservation station들과 reorder buffer(commit unit)은 효과적으로 레지스터 재명명을 제공한다.
- reservation station에 instruction issue가 진행될 때,
- 만약 피연산자가 당장 레지스터 뭉치(일반적인 경우)나 reorder buffer에서 값을 사용할 수 있다면,
- reservation station으로 복사된다.
- 이제 레지스터는 필요없으므로, 여기에 값이 다시 쓰여져도 된다.
- 아직 피연산자가 준비되지 않았다면,
- function unit에서 값을 가져와 reservation station으로 제공한다.
- 값을 끌어왔으므로, 다른 곳에서 필요하지 않다면 레지스터에 값을 쓰지 않아도 된다.
- (아마 다른 곳도 비슷한 타이밍이면 끌어와서 해결했을 듯. 먼 타이밍이면 쓰긴 해둬야할 듯..??)
📌 Speculation
- branch를 예측해서 막힘없이 계속 issue하는 것
- 제대로 branch 결과가 결정되기 전까지는 commit하진 않는다.
- Load speculation (적재추정)
- load와 cache miss의 delay를 방지한다.
- 유효주소를 예측한다.
- load 값을 예측한다.
- 다른(단계적으로 이전) store가 완료되기 전에 값을 load한다.
- 원래 load에서 레지스터에 값이 쓰일 단계는 생략한다.
- 추측이 확실시 되기 전까지는 load를 commit하진 않는다.
- load와 cache miss의 delay를 방지한다.
📌 Why Do Dynamic Scheduling?
※ 우리가 사용하는 대부분의 CPU은 수퍼스칼라 processor. 즉, 동적 방식을 사용함.
- 왜 그 전대로 컴파일러가 code를 scheduleing(static)하도록 하지 않고?? -> stall, 예외 예측 어려움
- 컴파일러가(실행 전에) 모든 stall들을 예측가능한 것이 아니다. e.g., cache miss는 runtime에서나..
- branch 주변은 항상 schedule할 수 있는 것이 아니다.
- branch 결과는 동적으로 결정되기 때문에.
- ISA별로 다른 구현방식은 각자 다른 latency(지연)과 hazard를 낳는다.
- 컴파일러가 모든 프로세서의 내부구조를 파악하고, 다른 구현방식별로 모두 대처하기 힘듦.
📌 Does Multiple Issue Work?
다중 issue는 동작하는가?
- 그렇다. 하지만, 완전히 활용되기는 어렵다
- 프로그램은 ILP(명령어 수준 병렬)을 제한시키는 의존성(dependency)을 갖고있기 때문.
- 몇몇 의존성은 제거하기 힘들다(hard to eliminate).
- e.g., pointer aliasing(다른 포인터가 실은 같은 곳을 가리키고 있는)
- 몇몇 parallelism은 활용하기 힘들다(hard to expose).
- instruction issue가 진행 중일 때 창 크기를 제한하는 것??
- 메모리의 delay와 제한된 bandwith
- pipeline이 full인 상태로(peak) 유지하기 힘들다(우리의 기대보다 덜 하게 된다).
- 추정이 잘 들어맞으면 도움을 줄 수 있다.
📌 Fallacies
착오
- pipelining은 쉽다??
- 기본적인 생각(basic idea)는 쉬움.
- 하지만 실제로 상세하게 파고들면 아주 어려움. e.g., hazard 감지해내기
- pipelining은 기술에 의존적이지 않다(independent of technology)??
- 그러면 왜 처음부터 동일한 pipelining이 아니었겠나..
- 더 많은 transister(트랜지스터, 반도체소자)는 더 발전된 기술을 가능하도록 한다.
- pipeline과 관련된 ISA 설계는 기술 양상(technology trend)를 고려해야 한다. e.g., predicted instructions
📌 Pitfalls
함정
- 안 좋은(poor) ISA 설계는, 파이프라이닝하기 더 힘들어지게 한다.
- e.g., 복잡한 ISA (VAX, IA-32)
- pipeline 동작을 만들기 위해 큰(significant) overhead가 발생한다.
- IA-32의 micro-op 방식.
- e.g., 복잡한 adressing 모델
- 레지스터 발전의 부작용, 간접참
- e.g., delayed branch(branch의 결과를 기다려야 하는 것)
- 발전된 pipeline은 long delay slot을 사용하여 해결한다??
- e.g., 복잡한 ISA (VAX, IA-32)
📌 Concluding Remarks
끝맺으며
- ISA는 datapath와 control 설계에 영향을 준다.
- datapath와 control은 ISA 설계에 영향을 준다. (서로에게 영향을 준다.)
- pipelining은 parallelism을 이용하여 instruction의 throughput(처리량)을 늘리는 것이다.
- 같은 시간당 더 많은 instruction을 완수할 수 있게 한다.
- 하지만 한 instruction의 시간(latency)이 줄어드는 것은 아니다.
- Hazards: structural, data, control
- 명령어 수준 파이프라인(Instruction-Level Parallelism)에서 multiple issue와 dynamic scheduling
- 의존성(dependency)은 parallelism을 방해한다(peak 성능보다 실제로 낮게 동작한다).
- 복잡성(complexity)는 power wall로 향하게한다(전력소모가 늘어난다).